

Projects are something that is used to demonstrate and reinforce the skills and knowledge that we acquire through our learnings. Therefore, we must follow the correct approach to a particular project. Projects can be divided into many categories and especially when it comes to a machine learning project, we can have different approaches to different projects based on their requirements.
Talking about a broader picture, I would like to highlight the most basic and useful approach to any machine learning problem that can help yield a better understanding of the problem, better modeling, and hence better results.
Following are the recommended steps to ace a machine learning project:
Step 1: Problem Definition

The first and foremost question that should come to your mind after the process of data collection is, "What problem am I trying to solve"?
A clear understanding of the problem statement is essential to ensure that you are headed in the right direction. Just reading out the problem statement and rushing to the modeling and prediction process often leads to poor results. One should know what they are trying to achieve before they get started with the actual process.
A neat way to inculcate this habit is to start the project with the description of the problem statement to the best of your understanding.
Step 2: Know Your Dataset

Once you have a clear understanding of your problem statement, the next step is to know your dataset. Really know the data you are dealing with. One should be aware of all the features that the dataset contains that can have a direct impact on the end results of their model.
A neat way to implement this is to incorporate a data dictionary in your project. Data dictionaries allow you to have a detailed insight into the data. Even if you show your project to someone else who is not aware of the dataset you used would more likely be impressed seeing how well the features of the dataset have been explained in the data dictionary.
Step 3: Select an Evaluation Parameter

After defining the data dictionary, the next step is to set an evaluation parameter. One should know what defines the success of the project. One should know when to stop working on its improvement and when the model has reached its maximum efficiency.
A separate portion should be dedicated to setting the standard of the evaluation metric that is being used to define the success of a project. An instance can be mentioning that a classification project will be deemed successful if it attains an accuracy of 95%.
Step 4: What features should we model?
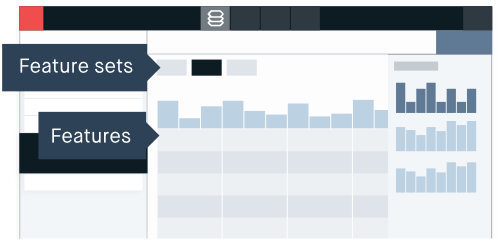
Now, this step is one of the most important steps in the machine learning project framework. This is the step that often determines how well your model will be performing. After going through the process of knowing your data and defining the data dictionary, one should be aware of the important features of the dataset. We just can't assume that all the features given in the dataset have an equal impact on the end results.
Some features in a dataset can be very important from the result's point of view while some can be redundant and add no value whatsoever to the predicting capabilities of the model.
One should carefully extract out the important features from the dataset before splitting the data and training the model on the features variables.
Step 5: Model Selection
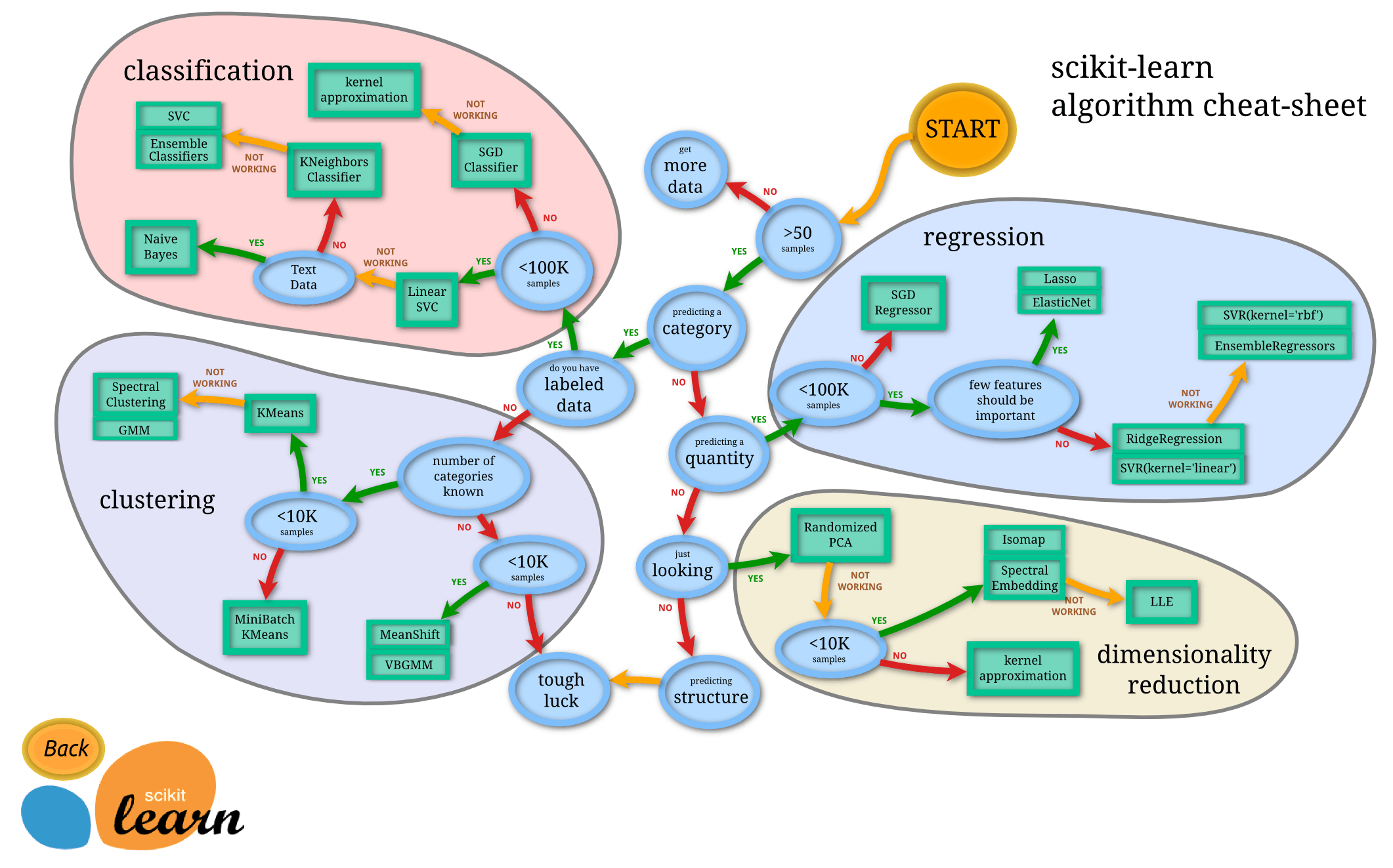
This is the step where you need to decide which machine learning algorithm to use. This decision should be driven by two parameters:
The type of problem being solved in the project.
The type and size of the data being dealt with.
Scikit-learn provides a machine learning model map that should be referenced before choosing the algorithm to use.
Choosing the right estimator/algorithm can help realize better results as different algorithms go differently with different types and sizes of data.
One can also train multiple models on the same data and then compare the evaluation metrics and decide which model is best suited for their problem but this process would require more time and compute power.
Step 6: Experimentation

The experimentation stage almost marks the end of a machine learning project. This is the stage where one is required to search for answers to questions like, "Is there any way to improve the current model?", "How far can the hyperparameters be tuned?", "Can more data be collected to have better results?", "Is there any other algorithm that can have better results?", and many more.
This is the stage where you need to work your options out in order to reach or pass the set standard of the evaluation metric. If, for some reason, the set standard is no being met, then try to carve out reasons for not reaching the desired value.
This will help in gaining insights like, how enriched was your dataset, how well have you used the features, how well did the data fit the model, and what inferences can be made to increase the efficiency of future projects.
I hope it was informative! Thanks for your time!